论文链接:Deep Recurrent Q-Learning for Partially Observable MDPs
概要
作者发现目前强化学习的算法仅使用了有限的记忆,且对当前状态观测值的准确性有很高的要求,并为了解决这些缺点而提出了增加循环网络层的DRQN算法。通过增加记忆单元,DQN可以在POMDP(Partially Observable MDP)环境上有更好的表现。另外,对于在完全可观测环境训练而在部分可观测环境评估算法的情况,DRQN的性能衰减更少。
算法
DRQN将传统DQN中卷积神经网络层之后的一层改为LSTM,其他保持不变。
Stable Recurrent Updates
使用RNN后便需要考虑隐藏状态的问题。在评估阶段,RNN的隐藏状态会从回合初一直更新到回合末。但对于训练阶段,使用的数据不一定是完整的回合数据,因而每次更新时RNN初始状态的设定便成了问题。作者提出了两种更新方式。
- Bootstrapped Sequential Updates
这种方式在更新时只使用完整的回合数据,按时间顺序,每次更新使用上次的隐藏状态,没有初始状态设置的问题。
- Bootstrapped Random Updates
这种更新方式随机从回合中某一个时间点开始更新,RNN的初始状态被设置为0.
第一种顺序更新的方式优点在于不用考虑RNN隐藏状态的初始值,但使用连续经验就保有了前后数据的相关性,会导致更大的方差。
随机更新的方式遵从了随机采样的策略,但每次更新时RNN的 状态都必须被初始化为0,这增加了RNN在更长的时间段上学习的难度(因为记忆经常被重置)。
根据作者的实验,两种方式具有相同的实验表现。
Experiments indicate that both types of updates are viable and yield convergent policies with similar performance across a set of games.
为了降低复杂程度,最终作者选择了随机更新的策略。
分析
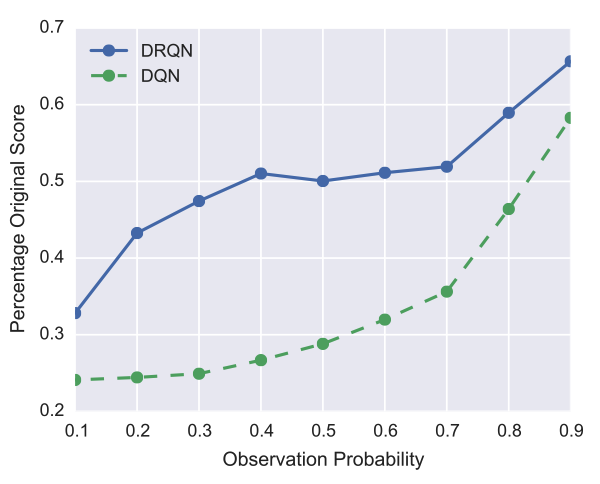
作者在pong上进行对比实验,训练阶段DQN与DRQN都在正常环境下训练,但在评估阶段按一定概率模糊游戏画面,从而将环境转化为POMDPs,根据实验结果,DQN与DRQN在这样的环境下都有性能损失,但DRQN的损失更小。