Ape-X: Distributed Prioritized Experience Replay
论文链接DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY
概要
本文提出一种分布式强化学习的方法,将强化学习的经验收集和训练拆分开来,并行的进行收集和训练任务,以生产者/消费者的形式通信。此外,通过增加经验收集任务的线程数量提高了经验收集的效率。
算法
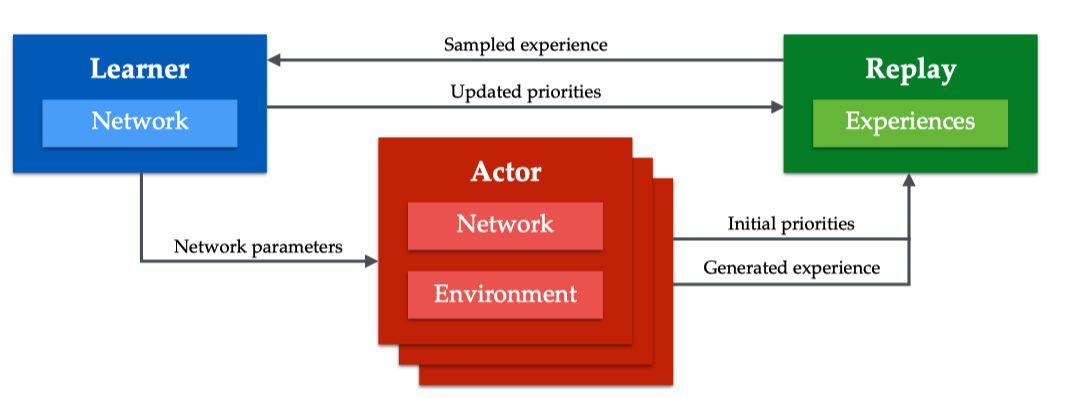
Actor定期从Learning处同步policy参数,并在环境上采样数据存入经验池。 Learner负责从经验池中采样经验来优化policy。 Learner和Actor完全并行执行。各自的算法如下:
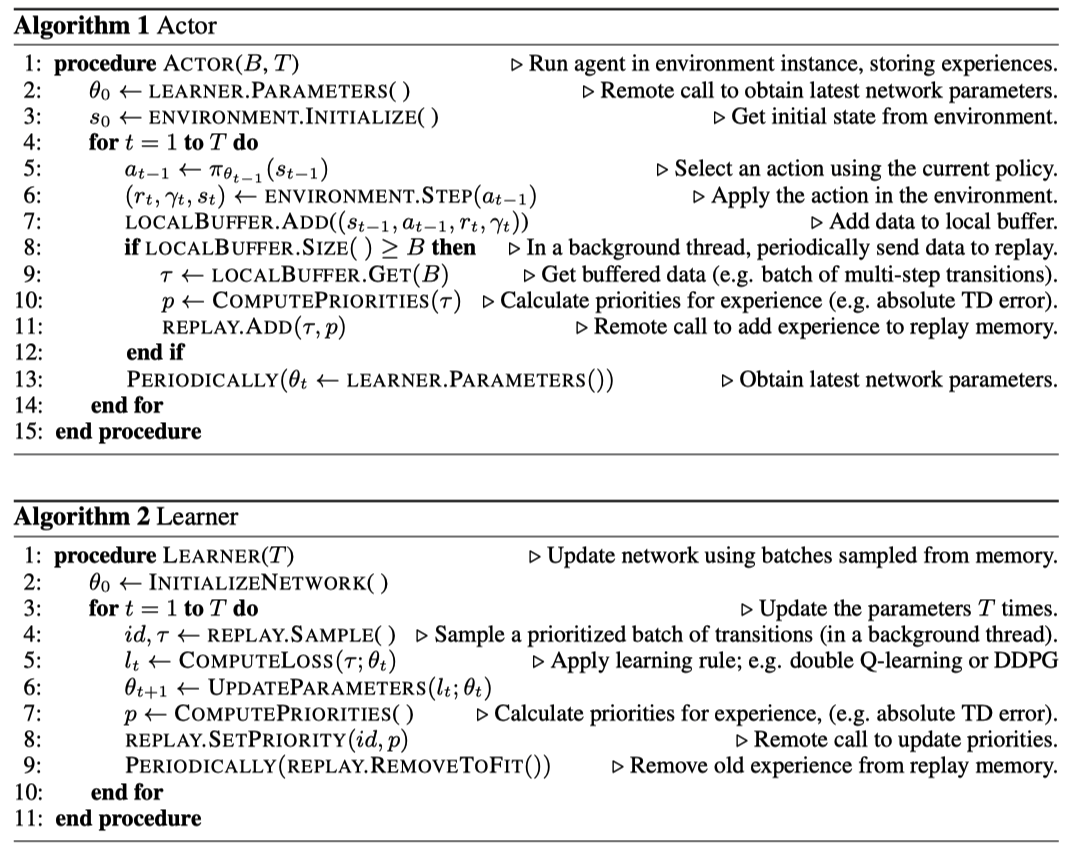
Ape-X除去并行化之外,相比于普通的Prioritized Experience Replay,还有两个优点。
- 在收集数据阶段Actor便会算出优先值。
- actor可以执行不同的策略
Ape-X的实现中使用到的tricks
- n-step estimation
- double Q-learning
- dueling architecture
- Prioritized experience replay