Dueling DQN:Dueling Network Architectures for Deep Reinforcement Learning
论文链接Dueling Network Architectures for Deep Reinforcement Learning
概要
本文提出了一种新的表示形式来在深度神经网络中表示强化学习的信息,即在神经网络的末尾,作者将网络分叉为两个链路,分别输出状态价值和每个动作的优势值,再求和得到Q值。作者认为这种网络架构更适合于无模型的强化学习。
网络架构的示意图如下
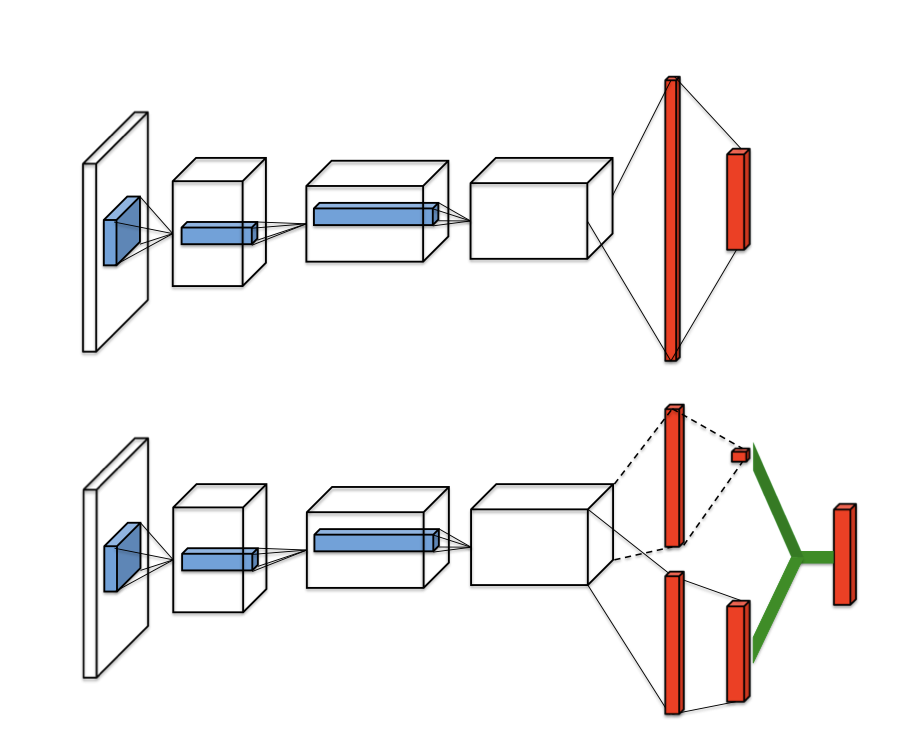
算法
本算法仅仅改变了Q网络的结构,算法仍然使用DQN算法。 值得注意的是在网络的状态价值与优势值求和时,对于一个Q值,状态价值和优势值可以任意调整。为了解决这种不确定性,作者提出了两种方式来限制优势值的范围。
- 强制最大的Advantage等于零,即让Advantage层的输出减去其最大值
- 强制Advantage的均值等于零,即让Advantage层的输出减去其均值
由于均值相对于最大值更加稳定,作者最终选用了后一种方式。
效果
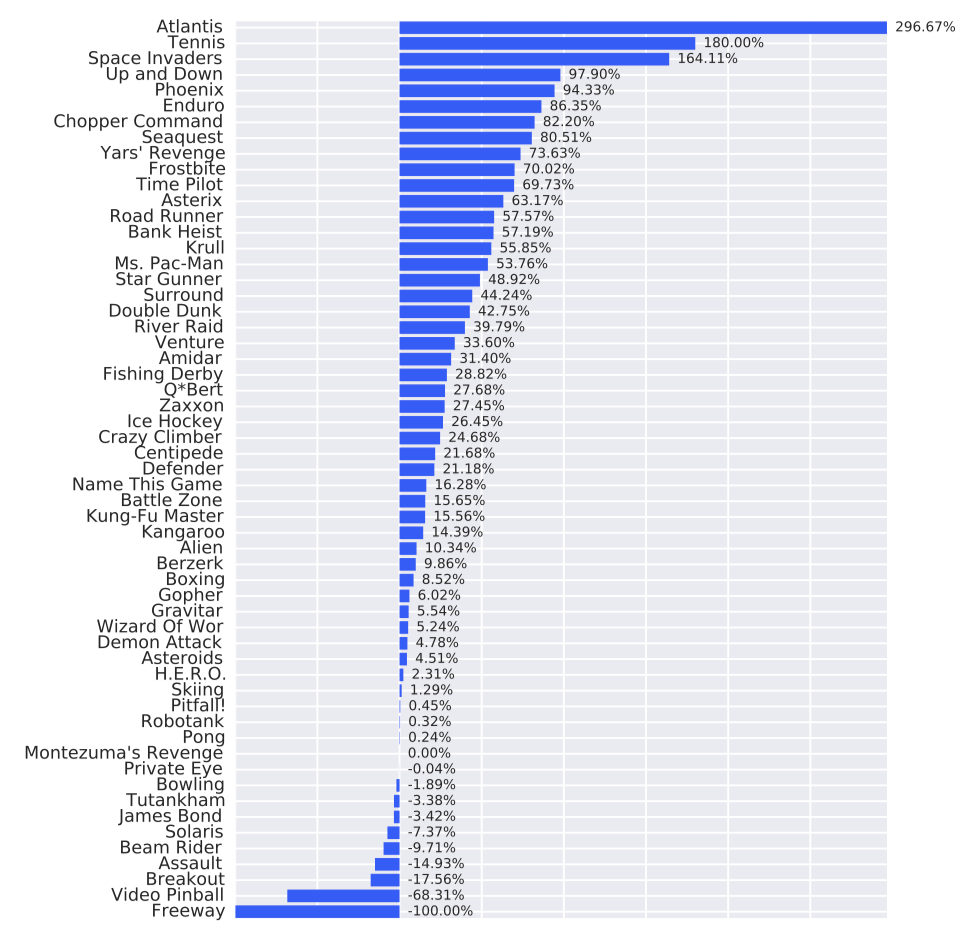
虽然仅在网络架构上做了调整,但许多环境下都取得了更好的效果。
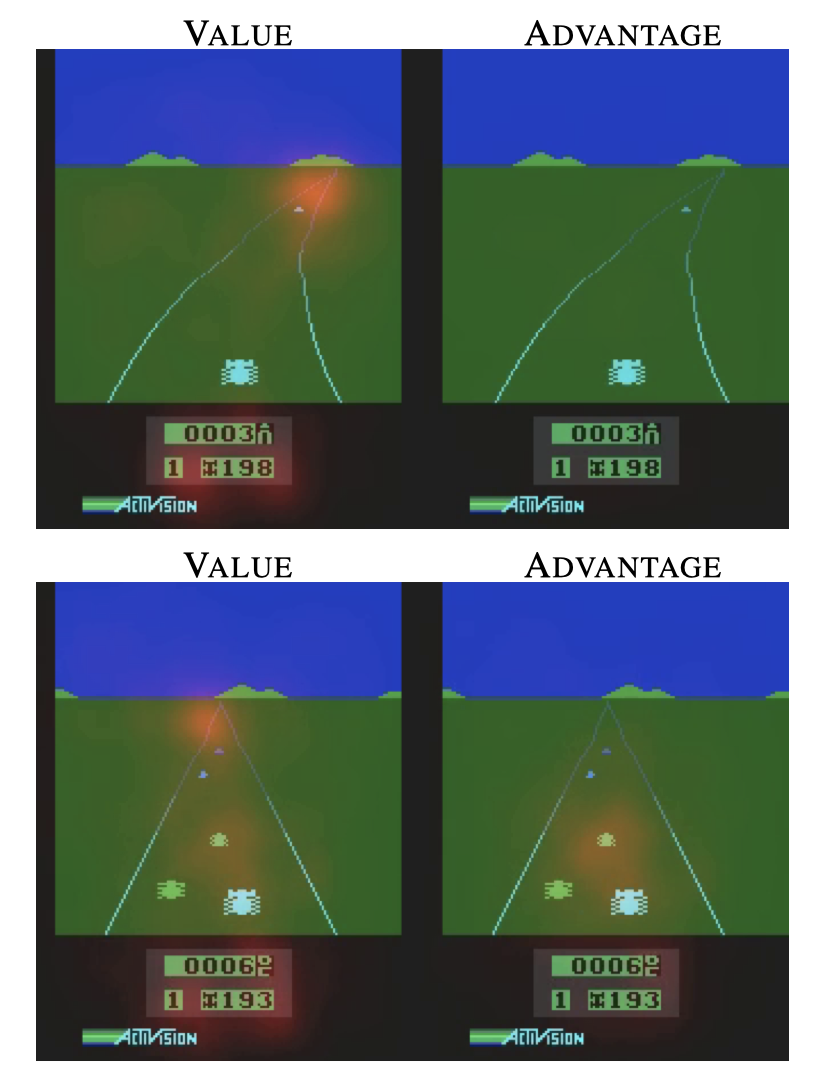
为了更好的理解本算法的优势,作者分析了在不同状态下state value和advantage的关注点。发现value net更关注道路情况而advantage更注意车辆情况。
核心逻辑代码
class DuelingQNet(nn.Module):
def __init__(
self, base_model, input_num, output_num, hidden_size=128, device="cpu"
):
super().__init__()
self.device = device
self.base_model = base_model
self.advantage_model = nn.Sequential(
nn.Linear(input_num, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_num),
)
self.value_model = nn.Sequential(
nn.Linear(input_num, hidden_size), nn.ReLU(), nn.Linear(hidden_size, 1)
)
def forward(self, s, state=None, info={}):
s = to_torch(s, device=self.device, dtype=torch.float32)
base_logits = self.base_model(s)
if isinstance(base_logits, tuple):
base_logits, state = base_logits
advantage = self.advantage_model(base_logits)
value = self.value_model(base_logits)
q = value + advantage - advantage.mean(1).unsqueeze(1)
return q, state