Game Analysis
星际争霸是一个实时策略游戏,玩家需要同时进行宏观的经济发展决策和数百个单位的精细操做. 游戏的策略存在明显的博弈性质,不同策略之间存在相互克制,且克制关系不具有传递性,即可以出现A>B>C>A这类环形克制关系.因此,通过简单的让智能体自我对弈很难得到强大的策略.
此外,游戏中只能获取不完全的环境信息,动作空间十分庞大且为组合形式(eg.主体+动作+目标),而且游戏中的宏观策略往往需要数千步的操作来执行,这些都是训练星际争霸智能体的难点.
Training Setup
通过将星际争霸游戏环境抽象为符合强化学习的范式,可以得到如下的结构.
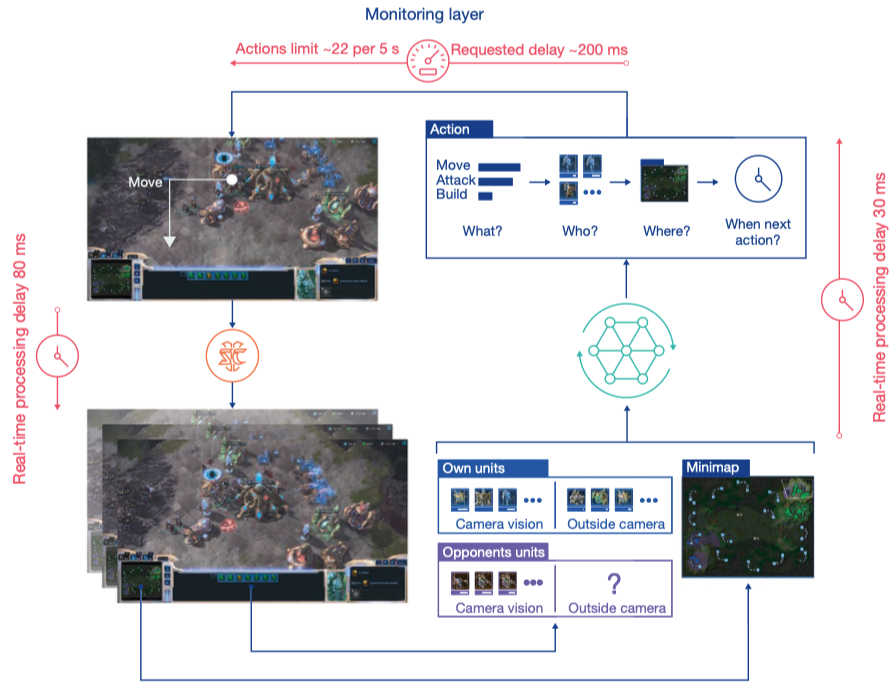
智能体观察各个单位的行动,以及minimap上的宏观视野,作出动作决策并传递给环境.
Observation
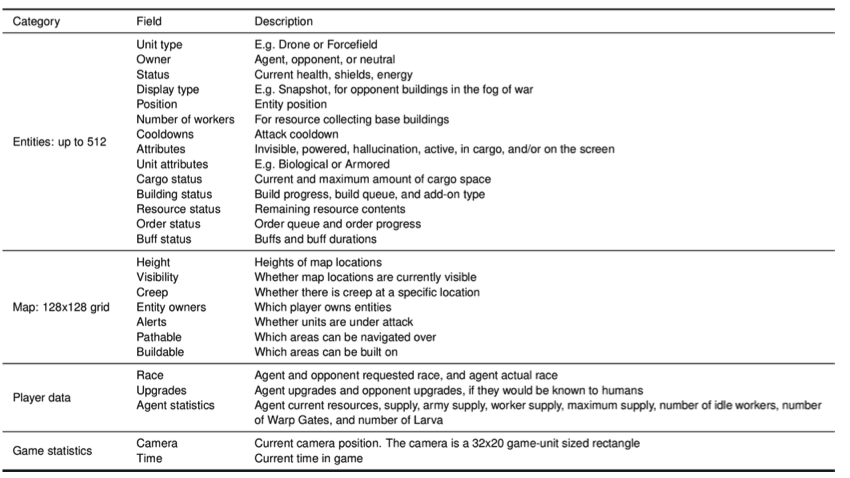
在每一个时序步骤中,AlphaStar智能体接受观测值$o_t$,其中包括了一系列可观测单位的各项属性值.这些信息是非完全的,不足以表示游戏的真实状态,一些不等观测到的地方单位不被包括在其中.
AlphaStar具体接受的各项信息如下表所示.
Action
星际中复杂的鼠标/键盘操作被抽象为了一种高度结构化的方式进行了表示,其中包括动作的类型,动作的主体,动作的位置,下一次观测和行动的时间间隔.这种动作表示方式导致了每步都有$10^{26}$这个量级的庞大动作空间.

Training Procedure
智能体首先使用模仿学习的方式学习人类玩家数据,再使用的强化学习方式继续训练.
模仿学习(监督学习)
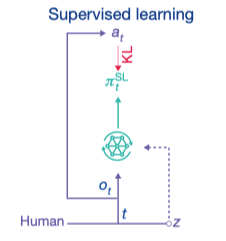
Deepmind发现直接使用self-play训练智能体的效果并不好,难以发现有效的策略,更难使用这些策略来战胜真实的人类玩家.即时是使用了具有庞大的智能体池(包括大量主agent和探索agent)的league算法也几乎无法在没有先验知识的情况下,在这样复杂的环境中找到优秀的策略.
于是AlphaStar首先对人类经验进行了模仿学习. 首先在 971000 条排名前22%的人类玩家的游戏数据上进行了监督学习,其次在16000条MMR分数高于6200分的顶尖玩家数据上进行了调优(fine-tune).
从结果上来看,只使用监督学习训练出的agent已经可以达到前16%的人类玩家水平.
Statistic z
Deepmind根据经验总结出Z Statistic这个统计数据,用来表示一个玩家的策略类型. 这个Z statistic包括了玩家的前20个建筑顺序和单位,以及建筑,技能等的升级顺序. 他们认为这些代表前期行为的数据大体上能够表示玩家为游戏全局设计的策略.
这个值在进行监督学习时有10%的可能被设置为0,用来避免其对智能体过分影响,使得智能体可以进行丰富的探索.
Reinforcement Learning
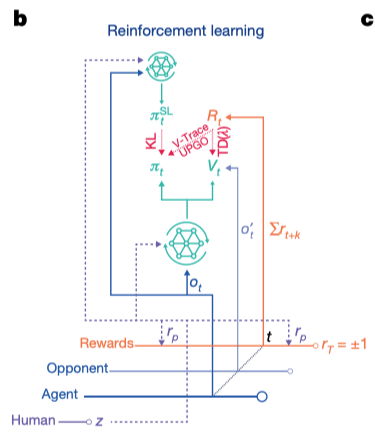
Reward:
-
输赢平分别获得-1,1,0的奖励
-
如果操作顺序与statistic Z符合,给予适当奖励.
-
KL 散度惩罚: 由于Deepmind认为人类经验对于StarCraft的十分重要, 他们以agent的策略与仅经过监督学习得到的策略之间的KL散度值作为一个惩罚项, 用以防止智能体的策略与监督学习的策略差距太大,从而避免无效的探索.
Algorithm :UPGO V-trace, offpolicy value update
Actor: $\pi_\theta(a_t|s_t,z)=\mathbb{P}(a_t|s_t,z)$
$s_t=(o_{1:t},a_{1:t})$为从开局到现在所有的observation和action.
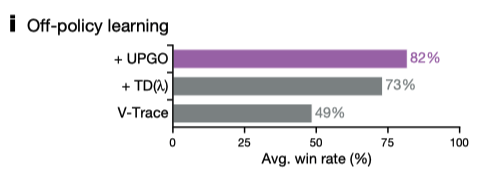
temporal difference learning (TD(λ)), clipped importance sampling (V-trace) , and a new self-imitation algorithm (UPGO)
Value and policy updates
训练过程中有actor和learner,actor有多个,进行异步的数据收集,learning负责更新神经网络模型参数. actor收集的数据会存入replaybuffer中,这些数据是off-policy的,需要进行重要性采样修正.
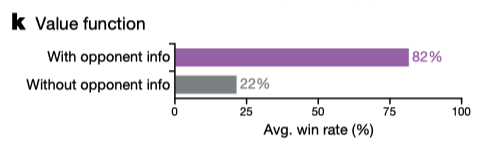
DeepMind提出了一种混合方式来解决这个问题,即对于policy的更新使用V-trace来进行修正,对于value function则直接使用$TD(\lambda)$来估计而不进行修正.
此外,为了减少Value估计的方差,估计时会同时使用对手的observation数据.需要指出这只会影响训练过程,因为在验证过程中不会使用value function,所以对比赛公平性没有影响.个人认为这类似于玩家在复盘游戏时开启游戏全部视野来反思自己的策略的过程.
从结果上看,使用对手的信息也起到了很好的效果.
Upgoing policy update(UPGO)
在V-trace的基础上, 借鉴了Self-Imitation Learning的想法,对于表现不好(低于状态价值)的动作回报进行截断,促进智能体更多地习好的经验.
\[ρ_t(G^U_t-V_\theta(s_t,z))\nabla_\theta log\pi_\theta(a_t|s_t,z)\]其中
\[G_t^U = \begin{cases} r_t+G^U_{t+1} & if \space Q(S_{t+1},a_{t+1},z)\ge V_\theta(s_{t+1},z) \\ r_t+V_\theta(s_{t+1},z) & otherwise \end{cases}\]\(ρ_t=min(\frac{\pi_\theta(a_t|s_t,z)}{\pi_{\theta'}(a_t|s_t,z)},1)\) $V_\theta$是V-trace计算出的Value,$Q(S_{t+1},a_{t+1},z)$由$r_t+V_\theta(s_{t+1},z)$来近似.
Self Play
对于starcraft这样的复杂游戏而言,丰富的游戏策略之间具有非传递性的克制关系,即A策略克制B策略,B策略克制C策略,但不一定A克制C策略,可能反而被C克制,就像剪刀石头布的关系一样. 对于这样的特性,一旦智能体在偏向于学习某一种更易于学习的策略A时,很可能由于自身对C策略熟练度不够而忽略了去学习如何应对这个克制自己的策略.
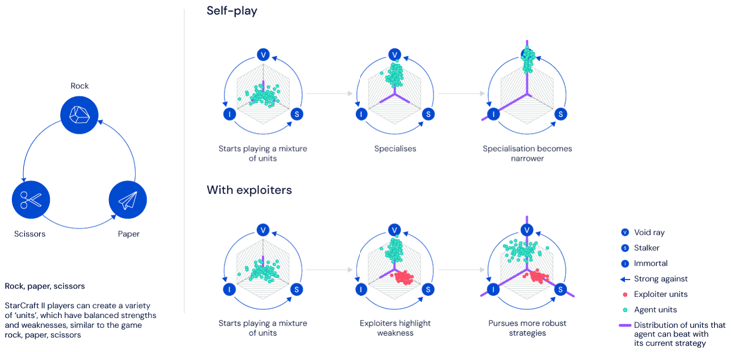
图中self-play这一行更生动的展示了上述情况,当Void ray策略被智能体深入学习时,由于缺乏强大的Stalker策略对手,所以忽略了对其的应对训练.这时如果我们加入用于发现自身策略漏洞的exploiters, 可以看到在with exploiters的情况下,克制当前智能体的红色Exploiter单元便促进了当前智能体去学习应对Stalker策略.
League training
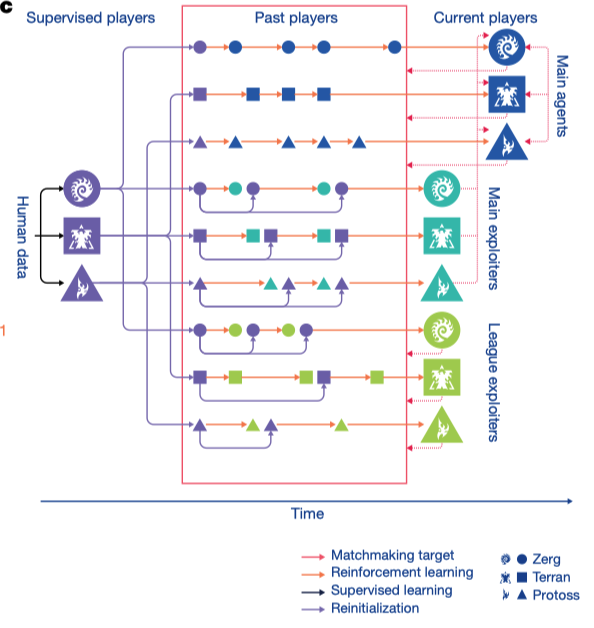
League Traing是DeepMind提出的基于简单的Fictitious Self Play(FSP)自我对弈算法针对星际争霸游戏而设计的新算法,用以促进策略的多样性,同时避免策略陷入循环克制而停止进步. 在训练过程中,通过一定规则保存训练中智能体的参数来不断的扩大整个league,并持续的计算league中智能体之间的胜负关系来动态的为需要训练的智能体匹配对手.
League 中共分了3中不同类型的智能体,负责不同的目标,同时进行训练,并产生自身的复制体加入league中.
- 主智能体(Main agents)
- 训练目标是成为最强的智能体
- 35% 的概率与自己对抗
- 50% 使用PFSP算法,从整个league中选择对手进行对抗
- 15% 使用PFSP算法,从目前难以抗衡的,过去的主智能体或主探索者进行对抗. 当没有难以抗衡的对手时则进行自我对抗
- 每经过¥$2*10^9$个训练步骤,便复制一份自身参数,加入到league中
- 不会重置参数
- 主利用者(Main Exploiters)
- 训练目标是发现主智能体策略的漏洞
- 100% 的概率对抗主智能体
- 如果一个主利用者对抗三个种族的主智能体都有70%的胜率,或者已经训练了$4*10^9$步,则加入到league中
- 在加入league之后,重置参数到监督学习模型的状态
- 联盟利用者(League Exploiters)
- 训练目标是发现整个联盟的弱点
- 100% 使用PFSP算法,从整个league的过去的模型中选择对手进行对抗
- 如果它对抗所有对手都有70%的胜率,或者已经训练了$2*10^9$步,则加入到league中
- 在加入league之后,又25%的概率重置参数到监督学习模型的状态
*实验配置: 1组main agent,一组main exploiter,两组league exploiter.一组为每个种族各一个agent. 使用32个v3 TPU训练44天,总计产生近900个agent.
prioritized fictitious self play(PFSP)
PFSP会按照以往胜率来分配对手,以避免一些无效对局浪费计算资源.
A选择某一个对手B的概率如下:
\[\frac{f(\mathbb{P}[A\space beats\space B])}{\sum_{C \in candidates}f(\mathbb{P}[A\space beats\space C])}\]其中f是权重函数.不同的f会产生不同的效果.
$f_{hard}(x)=(1-x)^p$这个权重函数会使得PFSP优先选择困难的对手,这样训练出得agent需要战胜所有的对手,而非最大化对抗所有对手的平均表现.默认PFSP使用这个权重.
$f_{var}(x)=x(1-x)$这个权重则会让agent更多的对抗实力相当的对手,避免被实力悬殊的对手碾压从而无法获得有用经验.通常对Main Exploiters和进步困难的Main Agents会使用这个权重.
另外从paper附录的伪代码中可以看到还有一种linear_capped的权重$f=min(0.5,1-x)$,从数值上来看,可以防止PFSP过分关注非常强的对手,减小无效对局的产生,League exploiters会使用这个权重.
Neural Network Architecture
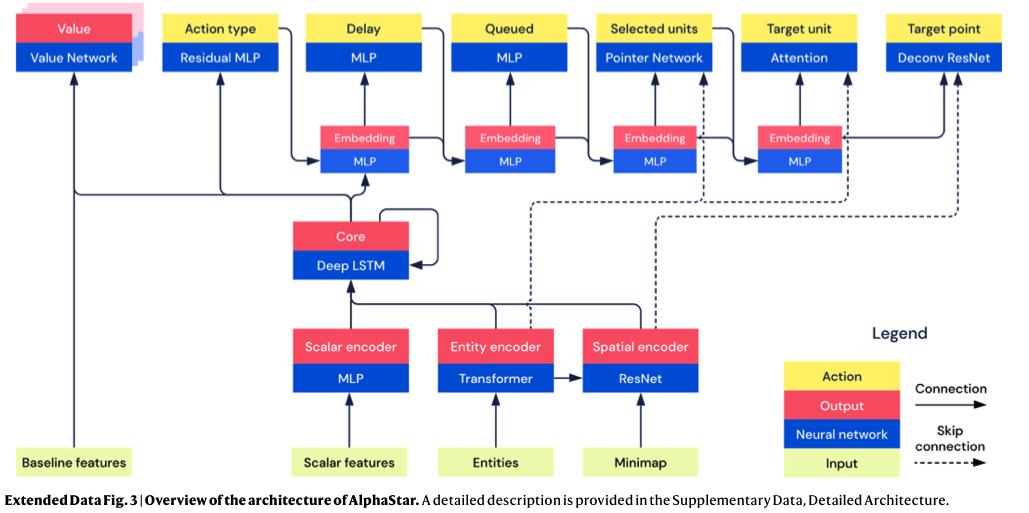
Our agent architecture consists of general-purpose neural network components that handle StarCraft’s raw complexity. Observations of player and opponent units are processed using a self-attention mechanism8 . To integrate spatial and non-spatial information, we introduce scatter connections. To deal with partial observability, the temporal sequence of observations is processed by a deep long short-term memory (LSTM) system9 . To manage the structured, combinatorial action space, the agent uses an auto-regressive policy 7,10,11 and recurrent pointer network12.
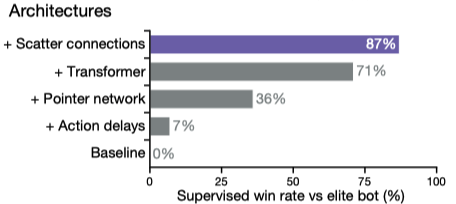
Infrastructure
For every training agent in the league, we run 16,000 concurrent StarCraft II matches and 16 actor tasks (each using a TPU v3 device with eight TPU cores23) to perform inference.The game instances progress asynchronously on preemptible CPUs (roughly equivalent to 150 processors with 28 physical cores each), but requests for agent steps are batched together dynamically to make efficient use of the TPU. Using TPUs for batched inference provides large efficiency gains over previous work.
Actors send sequences of observations, actions, and rewards over the network to a central 128-core TPU learner worker, which updates the parameters of the training agent.The received data are buffered in memory and replayed twice. The learner worker performs large-batch synchronous updates. Each TPU core processes a mini-batch of four sequences, for a total batch size of 512. The learner processes about 50,000 agent steps per second. The actors update their copy of the parameters from the learner every 10s.
instantiate 12 separate copies of this actor–learner setup: one main agent, one main exploiter and two league exploiter agents for each StarCraft race. One central coordinator maintains an estimate of the payoff matrix, samples new matches on request, and resets main and league exploiters. Additional evaluator workers (running on the CPU) are used to supplement the payoff estimates.
通用性
- 网络结构可以在其他obs为图片,列表和集合信息组成的环境上使用
- League算法可以适用于任何多人游戏
- 模仿学习配合conditional变量一起进行学习
探索与多样性
使用人类数据来帮助探索以及保持策略多样性:
- 使用监督学习初始化policy
- 持续在训练中最小化与人类策略的KL散度
- 增加基于statistic z提供伪奖励,奖励基于建造顺序的编辑距离和其他累积数据的汉明距离.每个奖励有25%的概率启用,并且有单独的价值函数与损失用来学习.
We found our use of human data to be critical in achieving good performance with reinforcement learning 从实验结果上看,人类数据确实起到了至关重要的结果
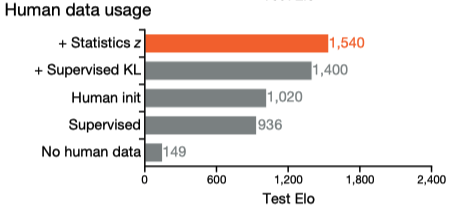
猜测:
- supervised: 只进行了监督学习
- Human init: 使用监督学习的参数进行初始化,再进行强化学习训练.
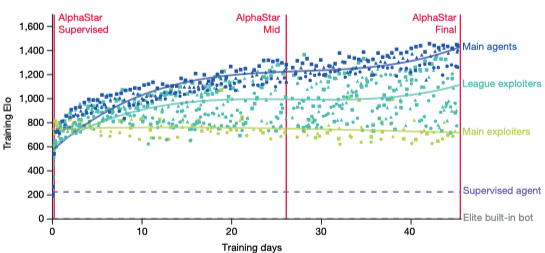
Elo Rating
总结
1.为杂observation space和action space的处理提供了参考. 2.为监督学习与强化学习的结合提供了参考. 3.阐明了多智能体环境的自我对弈算法的问题并提出一种解决办法.
参考
Nature: Grandmaster level in StarCraft II using multi-agent reinforcement learning
AlphaStar: Mastering the Real-Time Strategy Game StarCraft II
AlphaStar: Grandmaster level in StarCraft II using multi-agent reinforcement learning