论文链接 Agent57: Outperforming the Atari Human Benchmark
概要
本文提出了一个新的强化学习算法,首次在Atari的57个游戏环境上全部超越了人类水平。
问题
此前最新的NGU算法在部分难以探索的环境上已经取得了很大的进步,但仍然在部分环境中失败了,这表明它还不是一个足够通用的agent。作者认为一个重要的问题是,NGU在同时探索多个policy时,没有考虑到不同policy对学习的贡献程度,平均的将资源(在环境中探索和学习的机会)分配给各个policy。更好的方式应该是将资源更多的分配给学习的好的policy,避免资源被差的policy浪费。
新方法
-
对于上述多policy资源分配的问题,作者将其抽象为一个非稳态多臂老虎机问题来解决。
-
提出了一个新的参数化方式(即新的网络结构)用来解耦NGU提出的intrinsic奖励和环境的extrinsic奖励。
-
尝试使用了更长时间的记忆信息,并且结果表明这对性能也有一定的提升。
算法
State-Action Value Function Parameterization(separate nets)
在NGU中,reward的被定义为intrinsic reward和extrinsic reward的线性组合。$r_t=r_t^e+\beta r_t^i$,并且使用Q了网络来近似$r_t$的值。
本文中,作者将Q网络拆解成两个网络来分别拟合intrinsic reward和extrinsic reward。即
\[Q(x,a,j;\theta)=Q(x,a,j;\theta^e)+\beta_j Q(x,a,j;\theta^i)\]这两个网络具有相同的网络结构,在计算Retrace error时都使用target_policy$\pi(x)=argmax_{a\in\it{A}}A(x,a,j;\theta)$来选择下一步的action。
对于使用在Observe and Look Further中提出的h函数的情况,Q值的计算可以更严谨的写作:
\[Q(x,a,j;\theta) = h(h^{-1}(Q(x,a,j;\theta^e))+\beta_jh^{-1}(Q(x,a,j;\theta^i)))\]Adaptive Exploration over a Family of Policies(bandit)
NGU中一个核心的思想在于使用同一个网络架构同时训练具有不同探索倾向的过个policy。但作者认为对所有policy不分优先级的均匀训练是不合理的,提出了使用一个元控制器(meta-controller)来动态的挑选policy去参与训练和验证的方法。如NGU中的UVFA所示,各个policy本质上是具有不同$(\beta_j,\gamma_j)$的策略,元控制器的调整即是在根据训练进展和游戏环境动态的调整折扣率和探索/利用奖励的平衡。
对于元控制器的实现,作者采用的是以非稳态多臂赌博机算法(nonstationary multi-arm bandit algorithm)为模型,使用了滑动窗户UCB与$\epsilon$-greedy探索结合的算法。多臂老虎机的每一个臂$j$对应一组$(\beta_j,\gamma_j)$,它的回报为该policy在之后一回合游戏中完整的无衰减回报。也正是因为随着policy的不断更新,这个回报的分布是不断变化的,所以才使用了非稳态的多臂老虎机算法。
实现细节
policy设置:$\{(\beta_j,\gamma_j)\}_{j=0}^{N-1} ,\space N=32$,$\{\gamma_j\}$的范围是0.99到0.9999。
元控制器有两组设置,一组的滑动窗口大小$\tau =160 \space episodes , \epsilon=0.5$,另一组$\tau=3200 \space episodes, \epsilon = 0.01$
经验的长度从NGU的80个step(40个用于rnn状态恢复)改为使用160个step(80个用于rnn状态恢复)。
其他超参数与NGU相同,可以参考论文附录G.3,网络结构参考附录F。
分析
作者首先对比了Agent57,R2D2,NGU,MuZero算法在所有Atari游戏上的表现。结果如下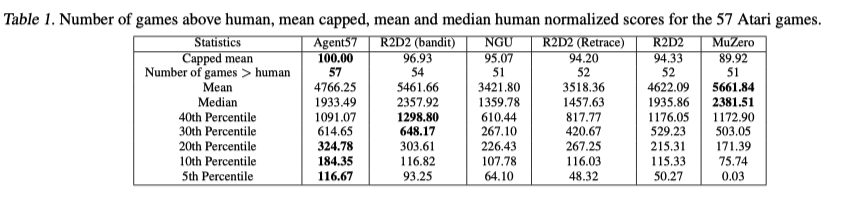
其中可以的得出几个结论:
- MuZero获得了总游戏得分的均值和中位数最高,但这是由于在某几个游戏上(如Beam Rider)MuZero获得了非常高的分数,MuZero在某些游戏(如Venture)上效果极差。
- R2D2在融合了元控制器后的R2D2(bandit)相比于R2D2(Retrace)表现得到了较大提升。
- Agent57在总体上获得了较高的分数,并且对于那些MuZero和R2D2无法学习的困难游戏上也取得了很好的表现,这足以证明Agent57是一个通用性很高的算法。
接着对比了NGU和Agent57在10个最具挑战性的游戏上的结果。
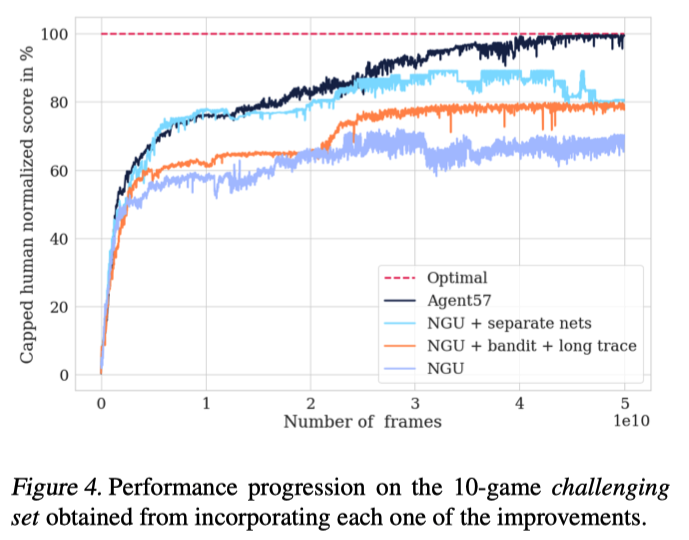
从中可以看出Agent57算法提出的每一项改进(sepetate nets, bandit)所产生的性能提升。
接着作者通过设计实验,详细分析了State-Action Value Function Parameterization这项改进对于性能的影响。这个实验环境为agent在一个网格世界探索,世界中只有一个网格区域有奖励,并且获得奖励后回合结束。在这个环境下,偏好探索的策略会探索所有区域,最后才进入有奖励的区域,偏好利用的策略会以最短路径进入奖励区域。通过让NGU与Agent57的两种参数化方式拟合按不同比例($\beta$)结合的intrinsic/extrinsic奖励,测试其在真实环境上的表现来衡量两种方式的性能。
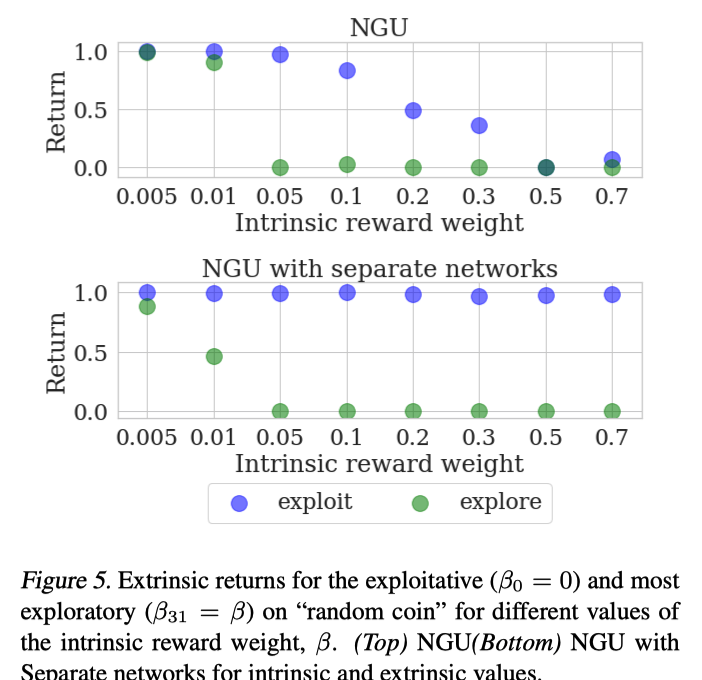
从结果中可以看出,用分离的两个网络来进行拟合时,$\beta$值的调整对于探索策略(绿色)的影响符合预期。 但随着$\beta$的增大,NGU中应用策略(蓝色)的效果受到了很大的影响而Agent57没有。NGU中的网络对于extrinsic奖励的拟合受到了$\beta$的影响,分离的两个网络可以更好的拟合intrinsic/extrinsic奖励。
对于RNN网络使用的经验窗口长度,作者也进行了实验,对比了n=80(NGU和R2D2中使用)和n=160两种情况。
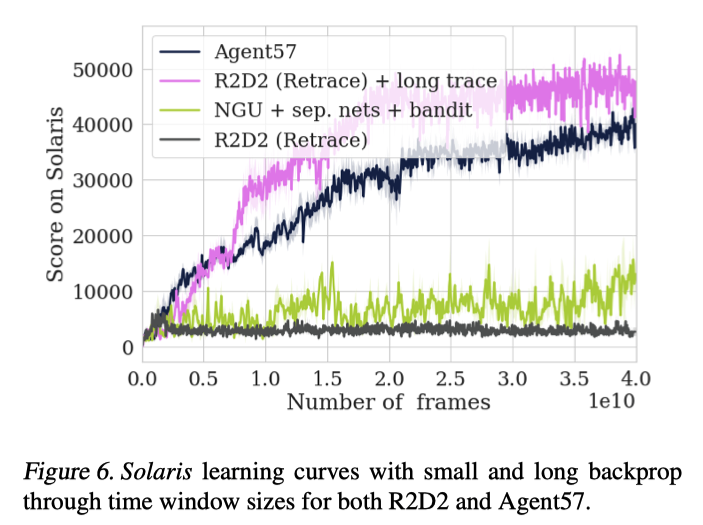
可以看出窗口长度的增大虽然在开始时减缓了训练速度,但训练具有更好的稳定性,并且最终结果也得到提升。
接下来,作者对于元控制器带来的影响单独做了实验
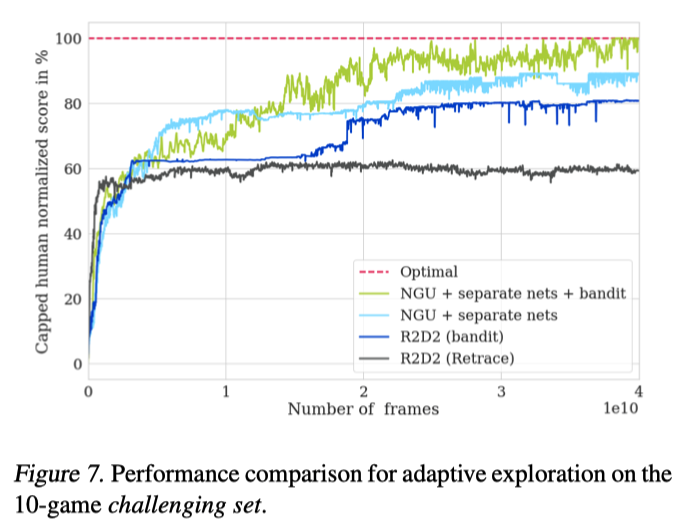
从结果可以看出,使用元控制器对于两个算法都有很大的提升。
随后作者进一步分析了元控制器为何如此有效,下图为元控制器在训练过程中的输出。图中纵坐标越大,$\beta,\gamma$的值越大。
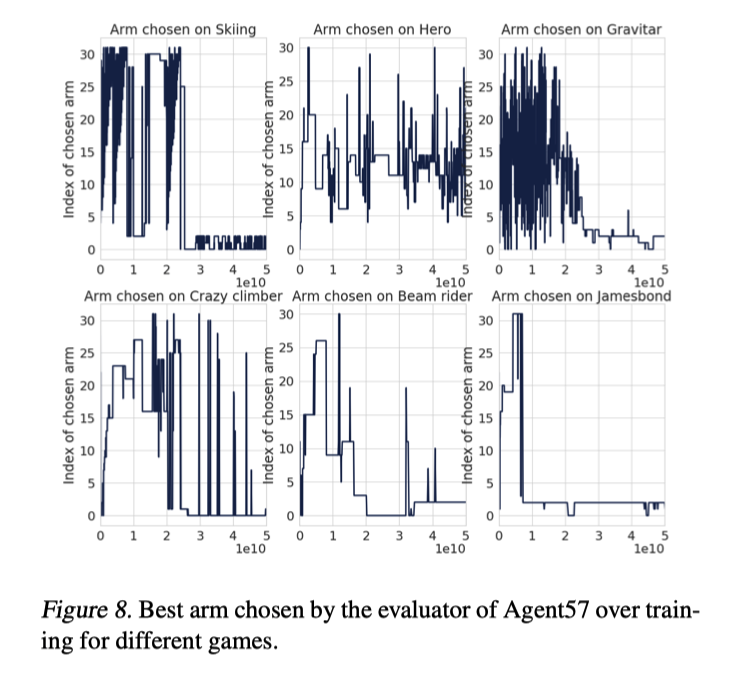
可以看出,元控制器可以在不同的游戏上进行了适应性的选择,并且在训练后期,元控制器的输出则集中在更偏好利用的策略上。这个非常符合人的直觉,也解释了为何元控制器会如此有效。
总结
本论文提出了一种基于NGU的改进算法Agent57,拆分了价值函数网络,引入了元控制器动态控制策略,并且使用了更长的经验窗口。Agent57是首个在Atari的全部57个游戏环境上都超越人类表现的算法。
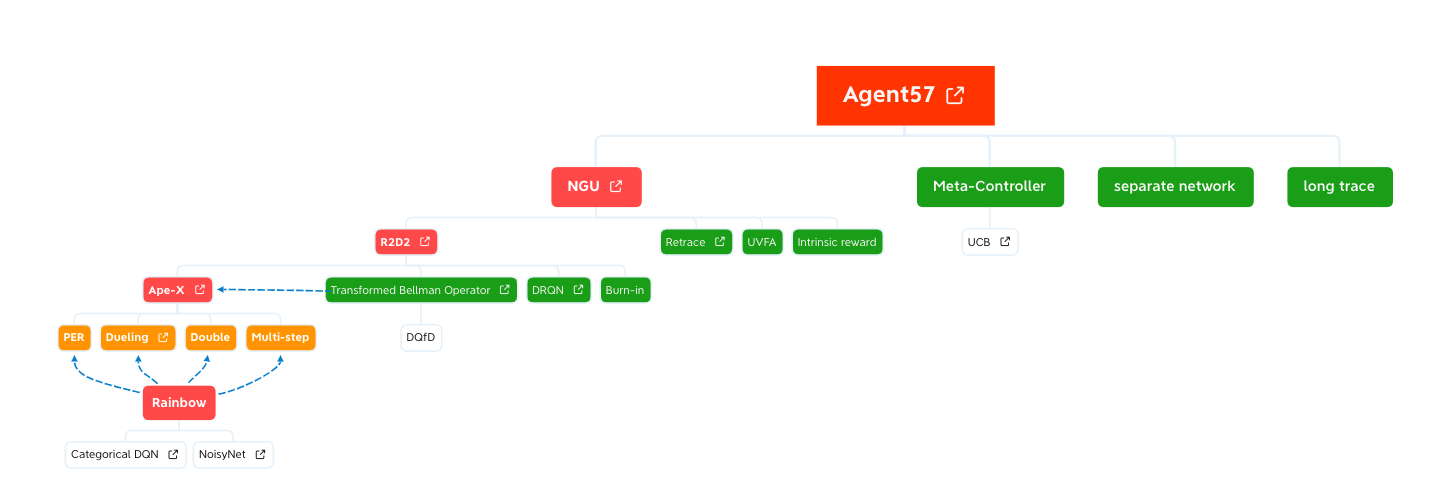
Agent57是一个(目前)集大成的算法,它与其他算法的关系如下图所示: