继DeepMind提出了League算法用以在星际争霸游戏中训练出顶尖AI后,腾讯开源了为多智能体环境进行自我对弈训练的框架TLeague.
论文TLeague: A Framework fro Competitive Self-Play based Distributed Multi-Agent Reinforcement Learning详细介绍了框架的设计思路和使用方法. 但还有不少细节并未在论文中作出解释.本文我将配合实际的使用经验对这个框架的运作流程进行进一步的解释.
框架纵览
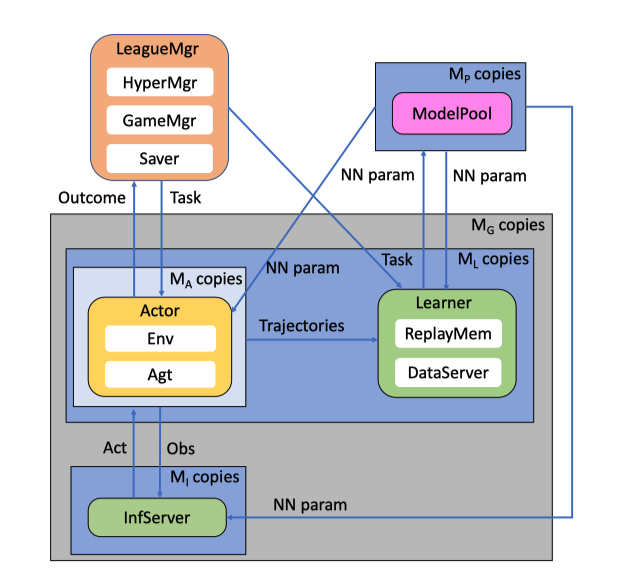
Tleague将训练框架分为了5个部分, LeagueMgr, ModelPool, Actor, Learner, InfServer. 他们之间相互独立,利用rpc(ZeroMQ库)进行网络通信来交换数据.
League Manager(LeagueMgr)
League Manager用来调度Learner和actor的任务, 并收集Actor上报的胜负结果.
Actor
Actor接受League Manager的发来的数据收集任务, 完成两个模型之间比赛对局, 收集比赛过程的数据供Learner训练模型, 并向League Manager上报比赛胜负结果, 最后又请求新的数据收集任务. 在存在InfServer的情况,Actor会将己方选手的obs等信息传给Infserver统一推理,再接受传回的Act.敌方选手的推理由Actor自己进行.
Learner
Learner接受League Manager发来的训练任务,准备对某一指定模型进行训练.待Actor把数据送到Learner的DataServer中后开始训练. 训练中不断将更新的模型推送到Model Pool. 在完成一定步数的训练后向League Manager请求新的训练任务.
Infer Server(Infserver)
Infer Server会想Leager manager查询某个Learner当前的task,并从ModelPool中获取这个task对应的模型.在收到actor发来的Obs数据后,使用这个模型进行推理并返回推理结果.
Infer Server并不是一个必须的组件,其目的主要是集中大量actor的obs,使用GPU来批量推理,从而达到加速训练过程的效果.
ModelPool
ModelPool是一个模型权重的数据库,作为其他组件间模型权重的传递媒介,以模型的id为索引,提供模型权重的远程读写功能.
启动流程
1. Model Pool启动
首先ModelPool需要启动,等待模型的推送和读取. 启动脚本非常简单,只需提供两个端口分别用于push和pull即可.其他组件通过ModelPoolAPI与它通信,非常方便.
python3 -m tleague.bin.run_model_pool \
--ports 10003:10004
2. League Manager 启动
其次启动LeagueManager,在其中需要指定自己的端口号和ModelPool的地址与端口,同时还有一些其他的配置项.可以参考examples中的示例.
python3 -m tleague.bin.run_league_mgr \
--port=20005 \
--model_pool_addrs=localhost:10003:10004 \
--game_mgr_type="${game_mgr_type}" \
--game_mgr_config="${game_mgr_config}" \
--mutable_hyperparam_type="${mutable_hyperparam_type}" \
--hyperparam_config_name="${hyperparam_config_name}" \
--restore_checkpoint_dir="" \
--save_checkpoint_root=./tmp-trvd-yymmdd_chkpoints \
--save_interval_secs=85 \
--mute_actor_msg \
--pseudo_learner_num=-1 \
--verbose=0
3. Learner启动
Learner启动时,需要指定对应的League Manager和ModelPool的地址与端口 还有自己的learner_id.可以参考examples中的示例. 可以同时启动多个learner,但id不能重复.
python3 -m tleague.bin.run_pg_learner \
--learner_spec=0:30003:30004 \
--model_pool_addrs=localhost:10003:10004 \
--league_mgr_addr=localhost:20005 \
--learner_id=lrngrp0 \
--unroll_length=2 \
--rollout_length=2 \
--batch_size=2 \
--rm_size=2 \
--pub_interval=5 \
--log_interval=4 \
--total_timesteps=2000000 \
--burn_in_timesteps=12 \
--env="${env}" \
--policy="${policy}" \
--policy_config="${policy_config}" \
--batch_worker_num=1 \
--norwd_shape \
--learner_config="${learner_config}" \
--type=PPO
*4. Infer Server启动
Infer Server不是必要的,如果要使用的化需要在Actor之前启动.启动时需要指定League Manager和ModelPool的地址与端口,还有对应的learner_id.可以参考examples中的示例.
python3 -m tleague.bin.run_inference_server \
--port=30002 \
--model_pool_addrs=localhost:10003:10004 \
--league_mgr_addr=localhost:20005 \
--learner_id="lrngrp0" \
--env="${env}" \
--is_rl \
--policy="${policy}" \
--policy_config="${self_policy_config}" \
--infserver_config="${self_infserver_config}" \
--batch_worker_num=1
5. Actor启动
Actor需在最后启动,需要指定League Manager, ModelPool, Learner的地址与端口.如果使用Infer Server,那它的地址端口也需要指定.可以参考examples中的示例.
python3 -m tleague.bin.run_pg_actor \
--model_pool_addrs=localhost:10003:10004 \
--league_mgr_addr=localhost:20005 \
--learner_addr=localhost:30003:30004 \
--self_infserver_addr=localhost:30002 \
--unroll_length=32 \
--update_model_freq=128 \
--env="${env}" \
--env_config="${env_config}" \
--interface_config="${interface_config}" \
--replay_dir=./tmp_trmmyy_replays \
--policy="${policy}" \
--policy_config="${self_policy_config}" \
--log_interval_steps=3 \
--n_v=11 \
--norwd_shape \
--nodistillation \
--verbose=0 \
--type=PPO
工作流程
Tleagu实际训练的过程可以说是Actor与Learner不断处理各自Task的过程.
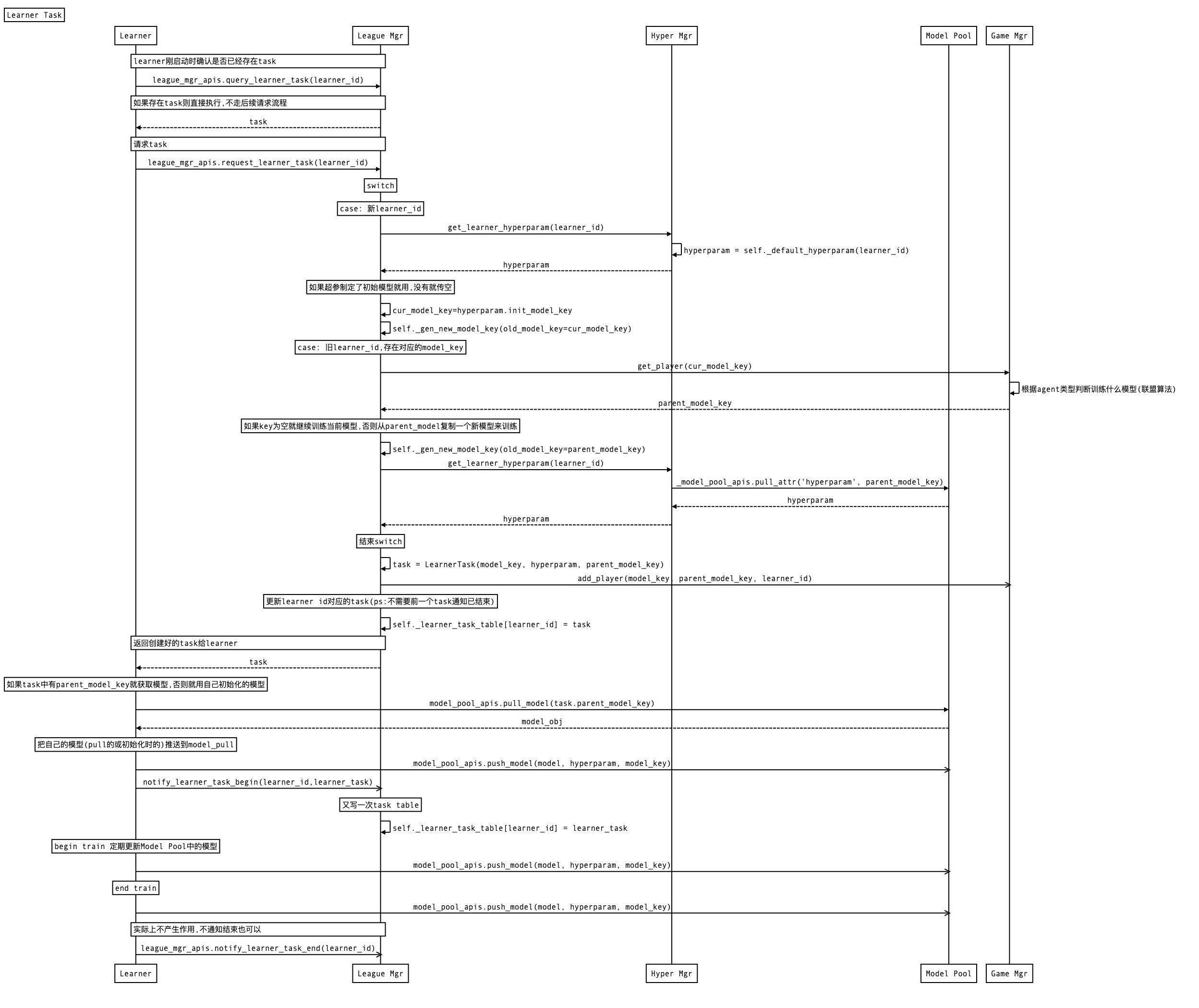
Learner Task处理
class LearnerTask(object):
def __init__(self, model_key, hyperparam, parent_model_key=None):
self.model_key = model_key
self.parent_model_key = parent_model_key
self.hyperparam = hyperparam
def __str__(self):
return str({'model_key': self.model_key,
'parent_model_key': self.parent_model_key,
'hyperparam': str(self.hyperparam),})
Learner 在启动后便会向League Manager请求task,然后不断进行训练与请求新task的循环. 其工作时序图如下:
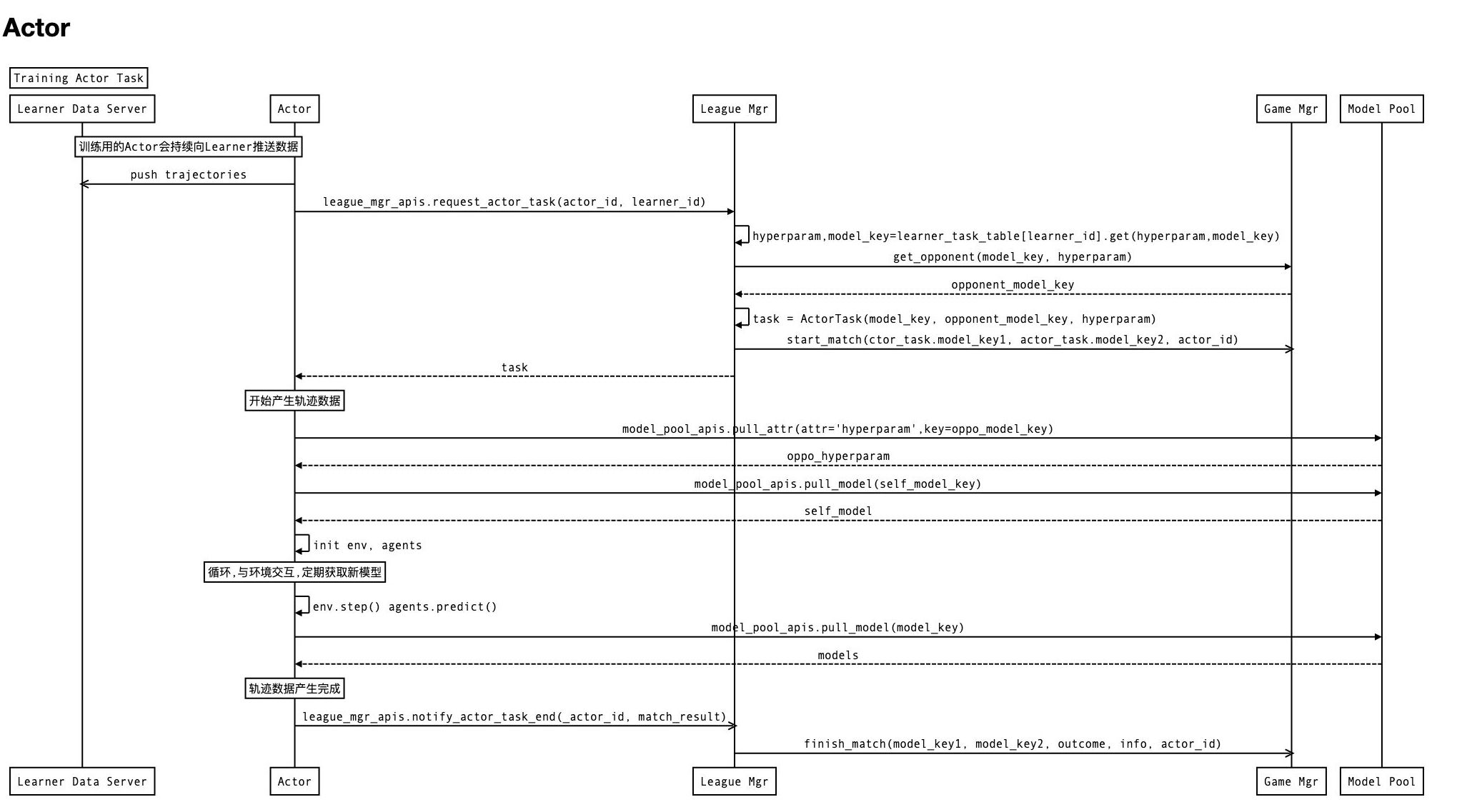
Actor Task处理
class ActorTask(object):
def __init__(self, model_key1, model_key2, hyperparam):
self.model_key1 = model_key1
self.model_key2 = model_key2
self.hyperparam = hyperparam
def __str__(self):
return str({'model_key1': self.model_key1,
'model_key2': self.model_key2,
'hyperparam': str(self.hyperparam)})
Actor在启动后,便会请求它对应的learner id的收集任务,随后不断进行收集数据,上报结果,请求新任务的循环. 其工作时序图如下.
Game Manager
League Manager 中负责调度训练任务中具体用模型的部分是Game Manager. 在League Manager需要为某个player分配对手时,便向Game Manager去询问对手的模型key.
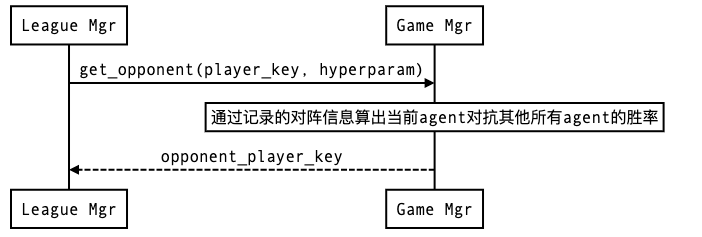
Tleague中提供了多种Game Manager,进行策略的对手调度.
Agent-Exploiter Game Manager(AEMatchMakingGameMgr)
这个Game Manager中对手的调度算法使用的是AlphaStar论文中提出的League算法,我在这篇博客中有过介绍.
结合Pytorch使用
TLeague框架本身提供的Actor与Learner都是基于TensorFlow 1.0的,使用并不是很方便,但各个组件间有良好的解耦,只要清楚了Learner与Actor如何处理Task,那完成就能在不修改其他组件的情况下,迁移到Pytorch上使用.