论文链接Recurrent Experience Replay in Distributed Reinforcement Learning
概要
作者展示了experience replay在参数延迟(网络参数在产生样本和进行优化之间的延迟程度)上的影响,发现其导致了表征偏移和循环状态过期。这将有可能最终导致训练稳定性和效果的下降。
随后作者实验了多种策略来减轻RNN在experience replay上的训练时遇到的上述问题。
最后作者提出了一个基于这些实验结果的强化学习算法R2D2(Recurrent Replay Distributed DQN),在Atari-57和DMLab-30上都取得了显著的优势。
算法
THE RECURRENT REPLAY DSTRIBUTED DQN(R2D2) AGENT
本文提出的算法与Ape-X类似,使用了分布式优先经验回放,n-step double Q learning(n=5)以及dueling网络结构。此外与DRQN相同,在卷积层之后加入了LSTM层。
由于使用RNN进行训练,存储的经验不再按照(s,a,r,s’)的形式存储,改为存储固定长度(N=80)的(s,a,r)序列作为一条经验,前后两条经验有40个step的重叠。
在此作者没有使用reward clipping,而是使用了Observe and Look Further中的提出的h函数来做reward rescaling.
\[h(z) = sign(z)(\sqrt{\|z\|+1}-1)+\epsilon z, \space \epsilon=10^{-2}\]在优先权重方面作者也做出了调整,使用了一个混合最大值与均值的TD-error: $ p=\eta\space max_i\delta_i +(1-\eta)\delta $ ($\eta$和$\alpha$设置为0.9) 其中$\delta_i$为一条经验中第i步的TD-error ,使用这个较激进方式来设置权重的原因是,作者发现使用更长的经验序列来训练时大误差也容易被冲淡,导致压缩priority的范围并且限制了优先值用于选择有用的经验能力。
This more aggressive scheme is motivated by our observation that averaging over long sequences tends to wash out large errors, thereby compressing the range of priorities and limiting the ability of prioritization to pick out useful experience.
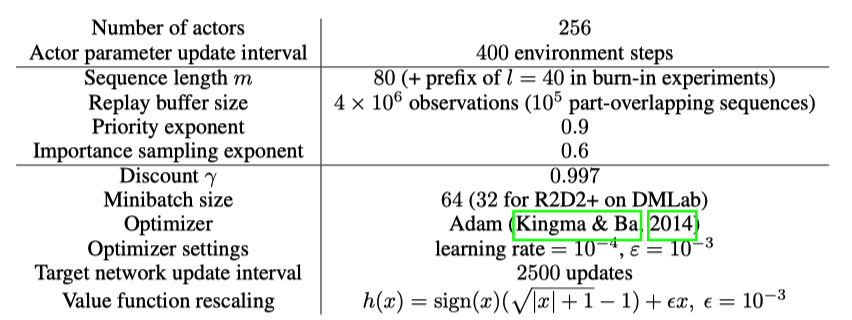
R2D2使用$\gamma = 0.997$,比Ape-X稍大。其他的超参数如下
RNN隐藏状态初始值的实验
增加RNN的使用可以帮助agent在POMDPs环境中更好的估计当前状态。RNN中隐藏状态记录了关于前序轨迹的信息,可以对当前观测值缺失的状态信息进行补充。 在DRQN论文中,作者讨论了使用RNN在训练强化学习过程中进行经验回放时的遇到的隐藏状态如何设置的问题。他们比较了两种策略。
- 使用完整的轨迹
- 随机采样各轨迹的片段,在采样的经验中使用0作为初始隐藏状态
并得出结论两种策略效果相似,为了降低复杂度选择第二种的方式。
本文作者则猜测,对于大多数完全可观测的atari游戏使用0作为初始状态是足够的,但这个策略在对记忆要求更高的领域可能会妨碍RNN学习更长期的依赖关系。
为了量化初始状态对于RNN的影响,作者提出了两种策略
- Stored state: 在收集经验时记录下RNN的隐藏状态,在训练时作为RNN的初始状态
- Burn-in: 将经验中轨迹的一部分用于给RNN恢复隐藏状态,使用剩下的部分更新网络。
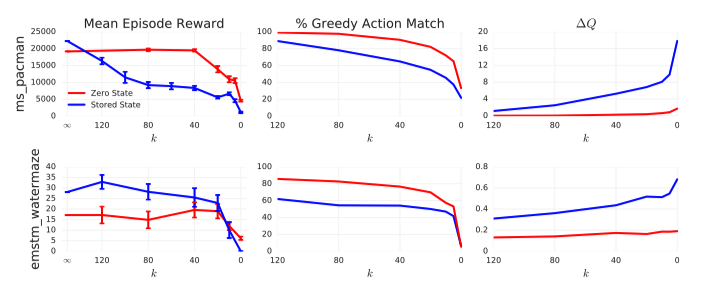
并比较了这两种策略与每一步都使用真实隐藏状态(经验收集时存储的状态)的RNN之间Q值的差异。 然后通过Q-value discrepancy指标进行比较:
\[\Delta Q= \dfrac{||q(\hat h_{t+i};\hat \theta)-q(h_{t+1};\hat \theta)||_2}{|max_{a,j}(q(\hat h_{t+j};\hat \theta))_a|}\]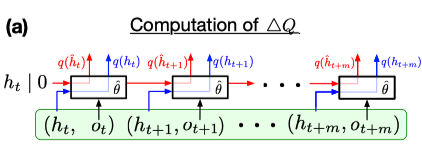

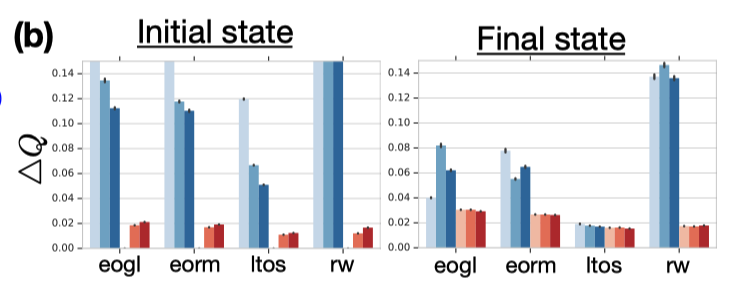
从上图中可以看出对于Q值的差异,使用Zero-State和Stored-State对于初始状态上的Q值影响很大,末状态上的影响相对较小。而burn-in策略对Q值的差异并没有明显的影响。
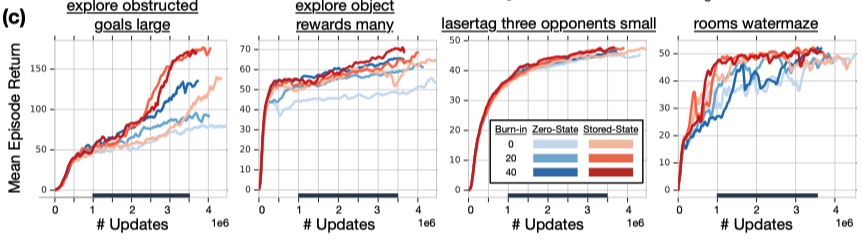
虽然从agent表现上来看burn-in策略不能减小Q值的差异,但对于agent的表现却有明显的提升。鉴于burn-in策略本质上是对于前N个状态不更新RNN参数,只计算隐藏状态,作者推断这个策略的优势在于防止RNN在初期不准确的隐藏状态下进行网络更新,从而提升了网络的表现。
对于Stored-State策略,可以看出它非常有效的减轻了隐状态的偏移,并且在游戏中也有更稳定的提升。这两个策略的结合最终获得了最为稳定的性能提升。作者也选择在R2D2中同时使用Stored-State策略和Burn-in策略(l=40).
分析
算法间对比
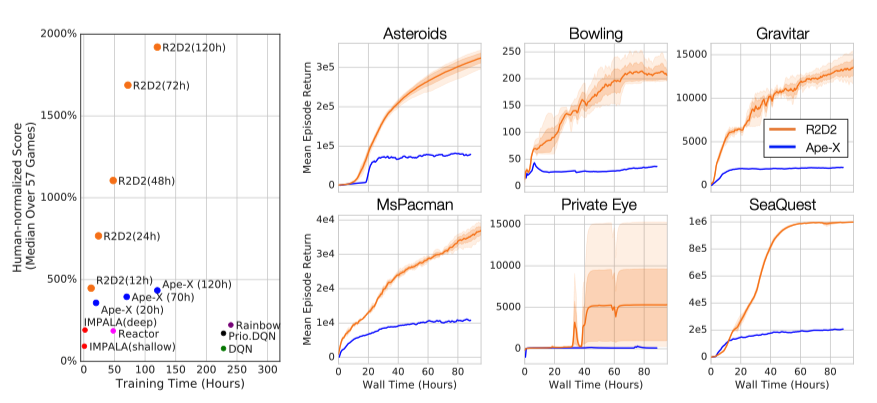
相比其他算法,可以看出R2D2取得了非常明显的效果提升。
算法内部成分的分析
atari-57作为一个相对简单的环境,几乎是完全可观测的,所以理论上记忆单元的提升效果有限,但实际上R2D2相比于Ape-X取得了很大的提升。于是作者又进行了两组实验。
第一组实验分析了R2D2各个成分对于性能的影响,作者分析了在1)gamma值不同,2)使用reward clipping,3) 去除RNN这三种情况下的性能差异。
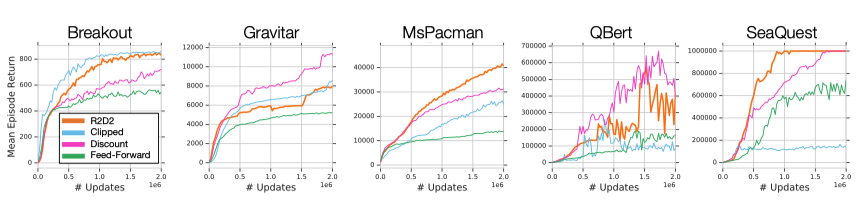
可以看出,RNN单元是对性能影响最大的,其他的成分在不同游戏上则有不同的效果。
第二组实验分析了RNN使用的历史信息长度对性能的影响。作者在MS-PACMAN(完全可观测)和EMSTM WATERMAZE(部分可观测)这两个环境上分别进行了实验,结果如下。
可以看出,即使在MS-PACMAN这个完全可观测的环境下,随着历史信息长度的下降,性能仍然会降低。这就表示agent对于记忆的使用方式并不简单(nontrivial)。agent可能会根据memory和obs的结合,学习到了更好的状态表示(state representation)。
总结
首先,作者发现使用0作为RNN的初始状态会导致对动作价值的错误估计,尤其是序列前部的状态。另外,如果不是用burn-in策略,那前期的错误隐状态可能会导致网络的破坏性更新。因此在经验池中应该记录RNN的隐藏状态,并且burn-in策略也有使用的价值。
其次,RNN的加入不止给agent提供了记忆之前状态的能力,还很有可能是的agent能够学到更好的状态表示,从而提升了性能。